We support Indexing API for grouping your documents in a custom manner in ArealAI.
If your organization is using this feature, we will group your processed documents into your desired index format.
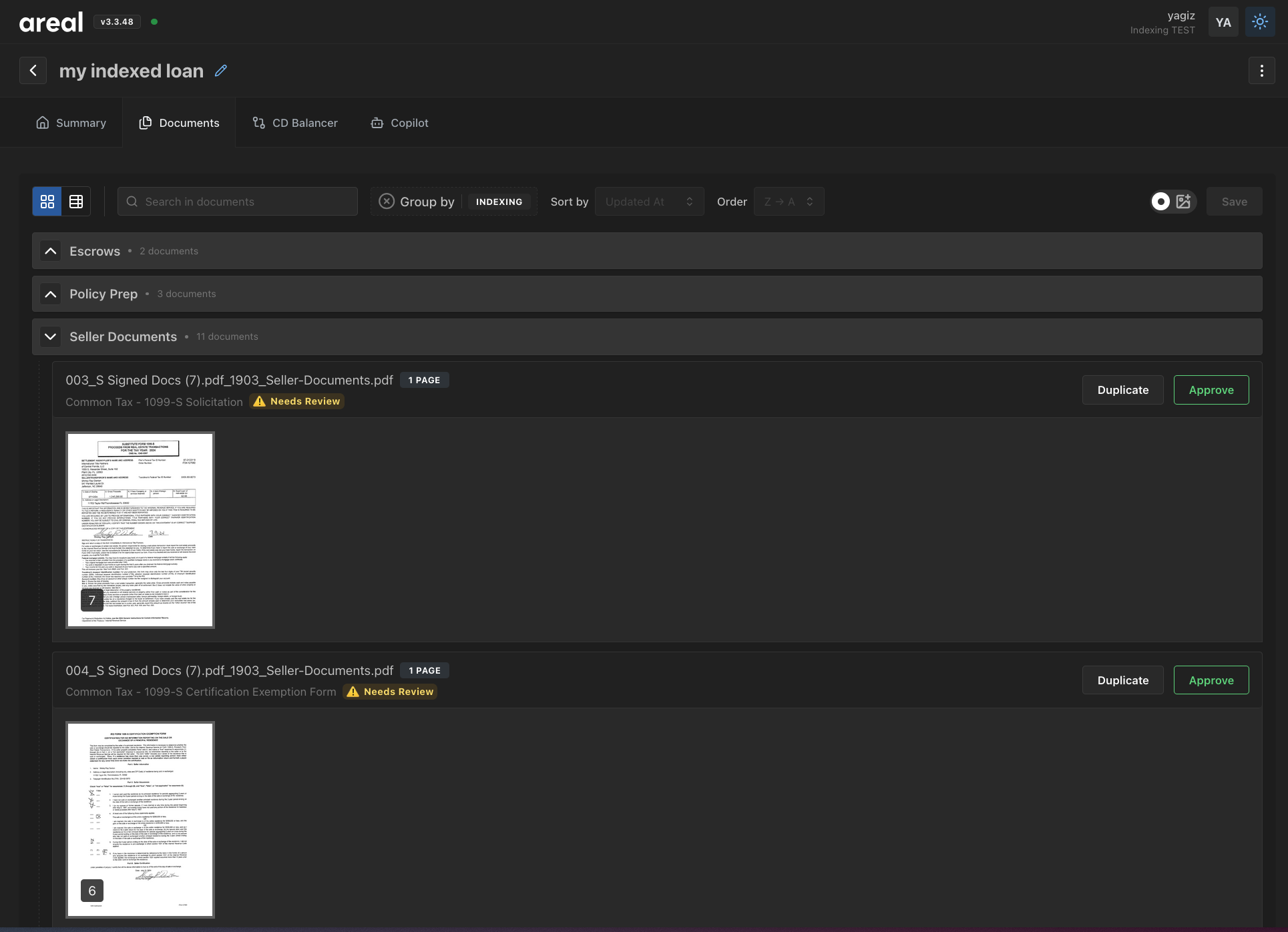
Example Views
Manage View
In ManageView you can move around the final documents within or across the indexes.
You can also duplicate the documents for easier organization.
Document Duplicatation
When you click on the "Duplicate" button for each document, we will create a new document with the same content.
We will add an indicator to reference the original document.
And you will be able to move this newly created document to a new index
Downloading Indexed Documents
Automatic Grouping
We provide an easy to use API to download the indexed documents in a zip file.
When group_by is set to index_id, we will put the documents in the same index into a folder.
importrequests# noqaSESSION_ID='66878f5e-c609-4796-9fc2-ecc6ae377cac'response=client.post(f'{BASE_URL}/sessions/{SESSION_ID}/download/',params={'group_by':'index_id'})withopen('documents.zip','wb')asf:f.write(response.content)print('✅ Zip file downloaded and saved as documents.zip')
usingSystem;usingSystem.Net.Http;usingSystem.Threading.Tasks;usingSystem.IO;usingSystem.Net;varsessionId="66878f5e-c609-4796-9fc2-ecc6ae377cac";varbaseUrl="http://dev-api.v2.areal.ai/api/v2";// Assume client is already authenticatedvarhandler=newHttpClientHandler{UseCookies=true,CookieContainer=newCookieContainer()};varclient=newHttpClient(handler);vardownloadUrl=$"{baseUrl}/sessions/{sessionId}/download/?group_by=index_id";varresponse=awaitclient.PostAsync(downloadUrl,null);response.EnsureSuccessStatusCode();varcontent=awaitresponse.Content.ReadAsByteArrayAsync();awaitFile.WriteAllBytesAsync("documents.zip",content);Console.WriteLine("✅ Zip file downloaded and saved as documents.zip");
importjava.net.HttpURLConnection;importjava.net.URL;importjava.io.FileOutputStream;importjava.io.InputStream;importjava.io.BufferedReader;importjava.io.InputStreamReader;importjava.net.CookieManager;importjava.net.CookieHandler;importjava.nio.charset.StandardCharsets;publicclassAutomaticGrouping{publicstaticvoidmain(String[]args)throwsException{StringsessionId="66878f5e-c609-4796-9fc2-ecc6ae377cac";StringbaseUrl="http://dev-api.v2.areal.ai/api/v2";CookieManagercookieManager=newCookieManager();CookieHandler.setDefault(cookieManager);// Assume client is already authenticatedStringdownloadUrl=baseUrl+"/sessions/"+sessionId+"/download/?group_by=index_id";URLurl=newURL(downloadUrl);HttpURLConnectionconnection=(HttpURLConnection)url.openConnection();connection.setRequestMethod("POST");connection.setDoInput(true);intresponseCode=connection.getResponseCode();if(responseCode==HttpURLConnection.HTTP_OK){try(InputStreaminputStream=connection.getInputStream();FileOutputStreamoutputStream=newFileOutputStream("documents.zip")){byte[]buffer=newbyte[4096];intbytesRead;while((bytesRead=inputStream.read(buffer))!=-1){outputStream.write(buffer,0,bytesRead);}}System.out.println("✅ Zip file downloaded and saved as documents.zip");}connection.disconnect();}}
Manual Grouping
You can easily download the indexed documents by filtering the documents by the index you want to download.
importrequests# noqaSESSION_ID='66878f5e-c609-4796-9fc2-ecc6ae377cac'# if you don't know your index_ids, fetch them from the sessionresponse=client.get(f'{BASE_URL}/sessions/{SESSION_ID}/',params={'group_by':'index_id'})response.raise_for_status()index_ids=list(set(o['index_id']foroinresponse.json()['objects']))# use them to filter documents by index_idindex_to_documents:dict[str,list[str]]={}forindex_idinindex_ids:response=client.get(f'{BASE_URL}/sessions/{SESSION_ID}/',params={'group_by':'index_id','filter_by.index_id':index_id})response.raise_for_status()document_ids=[o['id']foroinresponse.json()['objects']]index_to_documents[index_id]=document_ids# then download themforindex_id,document_idsinindex_to_documents.items():pdf_urls=[]fordocument_idindocument_ids:response=client.get(f'{BASE_URL}/documents/{document_id}/')response.raise_for_status()pdf_url=response.json()['pdf_url']# actual downloadprint(f'Downloading {pdf_url}...')response=requests.get(pdf_url)response.raise_for_status()print('File downloaded successfully')
usingSystem;usingSystem.Net.Http;usingSystem.Threading.Tasks;usingSystem.Text.Json;usingSystem.Net;usingSystem.Collections.Generic;usingSystem.Linq;varsessionId="66878f5e-c609-4796-9fc2-ecc6ae377cac";varbaseUrl="http://dev-api.v2.areal.ai/api/v2";// Assume client is already authenticatedvarhandler=newHttpClientHandler{UseCookies=true,CookieContainer=newCookieContainer()};varclient=newHttpClient(handler);// if you don't know your index_ids, fetch them from the sessionvarsessionsUrl=$"{baseUrl}/sessions/{sessionId}/?group_by=index_id";varresponse=awaitclient.GetAsync(sessionsUrl);response.EnsureSuccessStatusCode();varcontent=awaitresponse.Content.ReadAsStringAsync();varjsonDoc=JsonDocument.Parse(content);varobjects=jsonDoc.RootElement.GetProperty("objects").EnumerateArray();varindexIds=newHashSet<string>();foreach(varobjinobjects){indexIds.Add(obj.GetProperty("index_id").GetString());}// use them to filter documents by index_idvarindexToDocuments=newDictionary<string,List<string>>();foreach(varindexIdinindexIds){varfilterUrl=$"{baseUrl}/sessions/{sessionId}/?group_by=index_id&filter_by.index_id={indexId}";varfilterResponse=awaitclient.GetAsync(filterUrl);filterResponse.EnsureSuccessStatusCode();varfilterContent=awaitfilterResponse.Content.ReadAsStringAsync();varfilterJson=JsonDocument.Parse(filterContent);varfilterObjects=filterJson.RootElement.GetProperty("objects").EnumerateArray();vardocumentIds=newList<string>();foreach(varobjinfilterObjects){documentIds.Add(obj.GetProperty("id").GetString());}indexToDocuments[indexId]=documentIds;}// then download themforeach(var(indexId,documentIds)inindexToDocuments){foreach(vardocumentIdindocumentIds){vardocumentUrl=$"{baseUrl}/documents/{documentId}/";vardocResponse=awaitclient.GetAsync(documentUrl);docResponse.EnsureSuccessStatusCode();vardocContent=awaitdocResponse.Content.ReadAsStringAsync();vardocJson=JsonDocument.Parse(docContent);varpdfUrl=docJson.RootElement.GetProperty("pdf_url").GetString();// actual downloadConsole.WriteLine($"Downloading {pdfUrl}...");varpdfResponse=awaitclient.GetAsync(pdfUrl);pdfResponse.EnsureSuccessStatusCode();Console.WriteLine("File downloaded successfully");}}
importjava.net.HttpURLConnection;importjava.net.URL;importjava.io.BufferedReader;importjava.io.InputStreamReader;importjava.net.CookieManager;importjava.net.CookieHandler;importjava.nio.charset.StandardCharsets;importjava.util.*;importorg.json.JSONObject;importorg.json.JSONArray;publicclassDownloadingIndexedDocuments{publicstaticvoidmain(String[]args)throwsException{StringsessionId="66878f5e-c609-4796-9fc2-ecc6ae377cac";StringbaseUrl="http://dev-api.v2.areal.ai/api/v2";CookieManagercookieManager=newCookieManager();CookieHandler.setDefault(cookieManager);// Assume client is already authenticated// if you don't know your index_ids, fetch them from the sessionStringsessionsUrl=baseUrl+"/sessions/"+sessionId+"/?group_by=index_id";URLurl=newURL(sessionsUrl);HttpURLConnectionconnection=(HttpURLConnection)url.openConnection();connection.setRequestMethod("GET");connection.setDoInput(true);intresponseCode=connection.getResponseCode();if(responseCode==HttpURLConnection.HTTP_OK){BufferedReaderreader=newBufferedReader(newInputStreamReader(connection.getInputStream(),StandardCharsets.UTF_8));StringBuilderresponse=newStringBuilder();Stringline;while((line=reader.readLine())!=null){response.append(line);}reader.close();JSONObjectjsonResponse=newJSONObject(response.toString());JSONArrayobjects=jsonResponse.getJSONArray("objects");Set<String>indexIds=newHashSet<>();for(inti=0;i<objects.length();i++){JSONObjectobj=objects.getJSONObject(i);indexIds.add(obj.getString("index_id"));}// use them to filter documents by index_idMap<String,List<String>>indexToDocuments=newHashMap<>();for(StringindexId:indexIds){StringfilterUrl=baseUrl+"/sessions/"+sessionId+"/?group_by=index_id&filter_by.index_id="+indexId;URLfilterUrlObj=newURL(filterUrl);HttpURLConnectionfilterConnection=(HttpURLConnection)filterUrlObj.openConnection();filterConnection.setRequestMethod("GET");filterConnection.setDoInput(true);intfilterResponseCode=filterConnection.getResponseCode();if(filterResponseCode==HttpURLConnection.HTTP_OK){BufferedReaderfilterReader=newBufferedReader(newInputStreamReader(filterConnection.getInputStream(),StandardCharsets.UTF_8));StringBuilderfilterResponse=newStringBuilder();while((line=filterReader.readLine())!=null){filterResponse.append(line);}filterReader.close();JSONObjectfilterJson=newJSONObject(filterResponse.toString());JSONArrayfilterObjects=filterJson.getJSONArray("objects");List<String>documentIds=newArrayList<>();for(inti=0;i<filterObjects.length();i++){JSONObjectobj=filterObjects.getJSONObject(i);documentIds.add(obj.getString("id"));}indexToDocuments.put(indexId,documentIds);}filterConnection.disconnect();}// then download themfor(Map.Entry<String,List<String>>entry:indexToDocuments.entrySet()){StringindexId=entry.getKey();List<String>documentIds=entry.getValue();for(StringdocumentId:documentIds){StringdocumentUrl=baseUrl+"/documents/"+documentId+"/";URLdocUrlObj=newURL(documentUrl);HttpURLConnectiondocConnection=(HttpURLConnection)docUrlObj.openConnection();docConnection.setRequestMethod("GET");docConnection.setDoInput(true);intdocResponseCode=docConnection.getResponseCode();if(docResponseCode==HttpURLConnection.HTTP_OK){BufferedReaderdocReader=newBufferedReader(newInputStreamReader(docConnection.getInputStream(),StandardCharsets.UTF_8));StringBuilderdocResponse=newStringBuilder();while((line=docReader.readLine())!=null){docResponse.append(line);}docReader.close();JSONObjectdocJson=newJSONObject(docResponse.toString());StringpdfUrl=docJson.getString("pdf_url");// actual downloadSystem.out.println("Downloading "+pdfUrl+"...");URLpdfUrlObj=newURL(pdfUrl);HttpURLConnectionpdfConnection=(HttpURLConnection)pdfUrlObj.openConnection();pdfConnection.setRequestMethod("GET");pdfConnection.setDoInput(true);intpdfResponseCode=pdfConnection.getResponseCode();if(pdfResponseCode==HttpURLConnection.HTTP_OK){// File download logic here - save to appropriate locationSystem.out.println("File downloaded successfully");}pdfConnection.disconnect();}docConnection.disconnect();}}}connection.disconnect();}}